发布时间:2025-08-01 16:09:12
事情坏了。即使是经过充分测试的应用程序也会抛出意外错误,尤其是当它们出现在现实世界中为真实用户服务时。挑战不仅在于知道某些东西坏了, 还在于了解 原因 ,并在它影响到太多人之前修复它。
但这说起来容易做起来难。在微服务、第三方依赖项和不断的代码更改之间,找到根本原因就像解开一个移动的线程。当您的团队试图将事情拼凑起来时,用户正在流失,支持票证正在堆积如山,收入可能会消失。
这就是错误分析的用武之地——不仅仅是作为一种发现问题的方法,而且是一种发现模式、缩小原因和快速解决问题的系统。在这篇文章中,我们将介绍结构化的错误分析方法如何帮助团队减少停机时间并保护用户体验。我们还将向您展示可观测性如何帮助您减少猜测,以及 New Relic 等工具如何使整个过程更加高效、可靠和可扩展。
现代应用程序非常复杂,基于微服务、API、第三方集成和云基础设施构建。当某些东西坏了时,影响并不总是立即显现出来。一开始一项服务中的几 500 个错误可能会迅速像滚雪球一样发展成交易失败、用户沮丧和收入损失。而且这种收入损失会迅速增加。《 福布斯》的一份报告估计,大型企业的计划外停机成本约为 每分钟 9,000 美元 。 根据 Atlassian 的数据,即使是中型企业的成本也可能在每分钟 5,600 美元到 9,000 美元之间 ,具体取决于其行业和对数字服务的依赖程度 。但这不仅仅是钱的问题。重复或长时间的错误会损害用户信任,增加支持团队的压力,并减慢开发速度,因为工程师被从路线图工作中拉出来追查事件。此外,它还会玷污品牌本身。
这就是错误分析以及更广泛的可观测性变得至关重要的地方。根据 New Relic 2024 年可观测性预测报告 ,投资于全栈可观测性的团队解决中断 的速度提高了 18%。 公司还报告说 ,如果从一开始就将可观测性内置到他们的工作流程中,停机时间 减少了 79%,中断成本降低了 48%。
可观测性为您提供了全局,而错误分析则可以帮助您放大。它告诉您失败的地方 、 地点和 频率 ,将分散的错误信号转化为可作的见解。您无需猜测或依赖轶事报告,而是可以跟踪模式、确定根本原因并自信地解决问题。
如果做得好,错误分析将对话从被动调试转变为主动预防。这意味着更少的支持票证、更少的深夜页面以及更稳定的用户体验,所有这些都直接有助于业务绩效。
大多数工程团队早在知道 原因之前就知道出了问题 。当错误影响生产环境时,调查花费的时间比修复本身更长的情况并不少见。以下是一些最大的障碍:
错误远离其来源:
前端可能会显示 500 错误,但真正的问题可能隐藏在后端服务甚至下游依赖项中。报告错误的服务并不总是有问题的服务。如果没有对系统的全面可见性,工程师最终可能会追逐错误的事情,将时间浪费在症状上,而不是解决根本问题。
太多断开连接的工具:
团队通常会在指标、日志、跟踪、警报、部署历史记录和事件报告的仪表板之间切换,所有这些都位于不同的系统中。每个工具都有部分答案,但没有一个地方能说明全部情况。这种工具的蔓延导致了孤立的见解、遗漏的模式和漫长的分类周期。
日志和跟踪中缺少上下文:
即使找到正确的日志行或跟踪,也可能不清楚是什么触发了它。这些日志中通常缺少关键上下文,例如用户标识、最近的部署、请求路径或功能标志。如果没有这一点,当它实际上是更大问题的一部分时,错误可能看起来是孤立的。
手动调试无法缩放:
对于较小的团队或整体系统,基于直觉的调试可能会起作用。但是,当您运行数十个具有复杂相互依赖关系的微服务时,直觉和部落知识就会分崩离析。误差范围较小,爆炸半径较大。
时间已经在流逝:
调查错误所花费的时间不仅仅是工程成本,更是业务成本。停机的每一分钟都意味着交易丢失、用户沮丧和 SLA 紧张。即使问题得到解决,缺乏明确的根本原因也意味着问题可能会再次出现。
这些挑战清楚地表明了一件事:如果没有一种有针对性的错误分析方法,一种将上下文、相关性和可见性结合在一起的方法,你总是落后于问题几步。
解决根本原因不仅仅是拥有数据,还涉及减少从检测到理解所需的时间和精力。团队将错误连接到其源头的速度越快,他们就能越早恢复可靠性并避免重复出现问题。
New Relic 通过将错误、跟踪和日志等关键信号对齐到一个连接的工作流程中来支持这一点,该工作流程旨在实现快速调查和对诊断的高置信度。平台上的多个工具有助于此工作流程,包括:
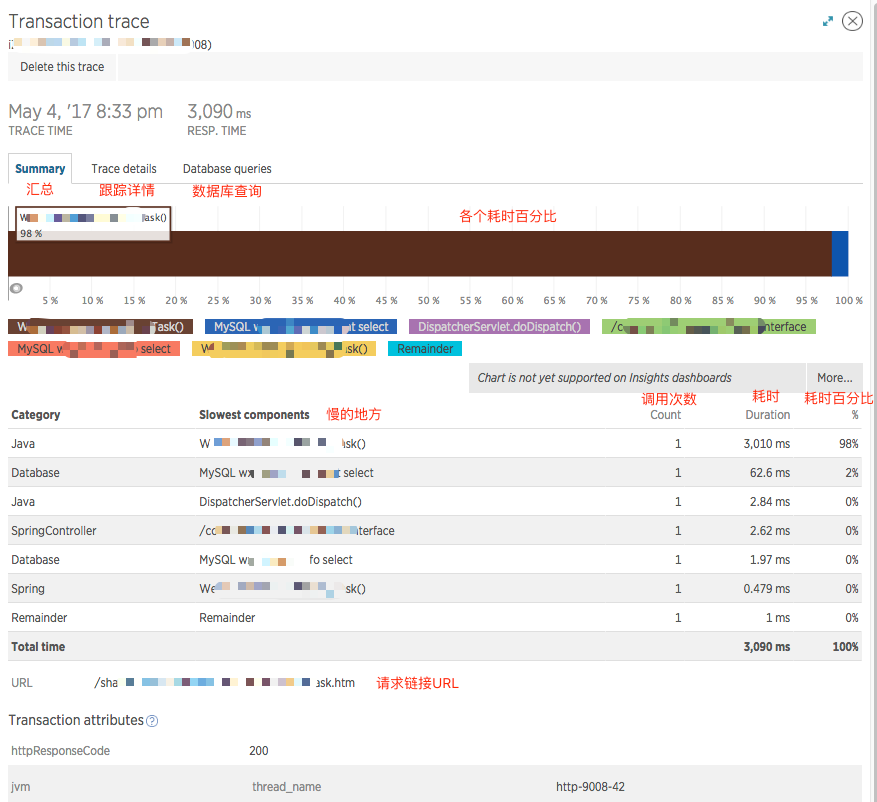
在高速环境中,分散的错误警报可能会减慢团队速度。Errors Inbox 通过将 APM、浏览器、移动和无服务器工作负载中的错误整合到一个结构化视图中来解决这个问题。类似的错误会自动分组以减少噪音,并包含堆栈跟踪、用户影响和部署标记等元数据,以提供即时上下文。按工作负载、版本和环境划分的内置过滤器可帮助团队快速发现回归,而分类状态以及与 Slack 或 Jira 的集成等协作功能则支持共享所有权和更快的解决。下图显示了“广告服务”的典型错误收件箱视图,说明了错误趋势和特定异常情况。
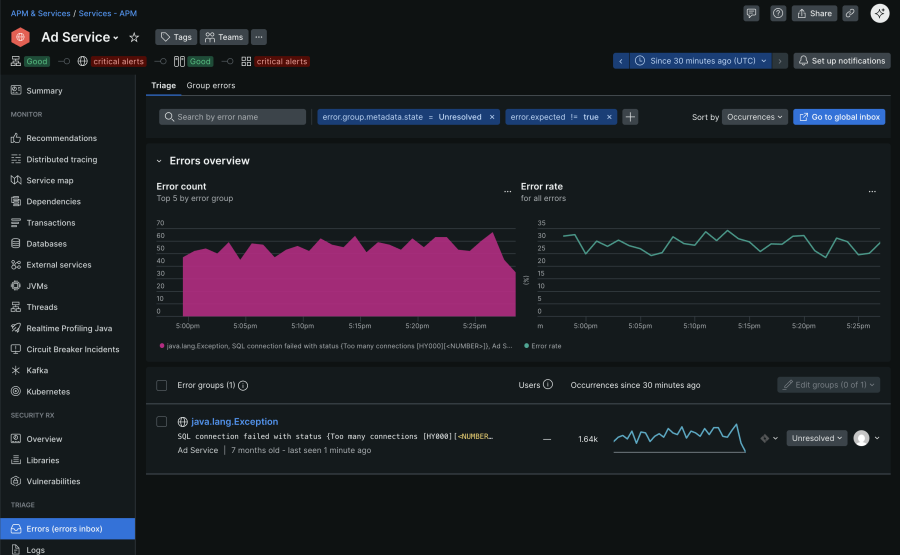
在我们的文档中详细了解如何通过错误跟踪来响应中断 。
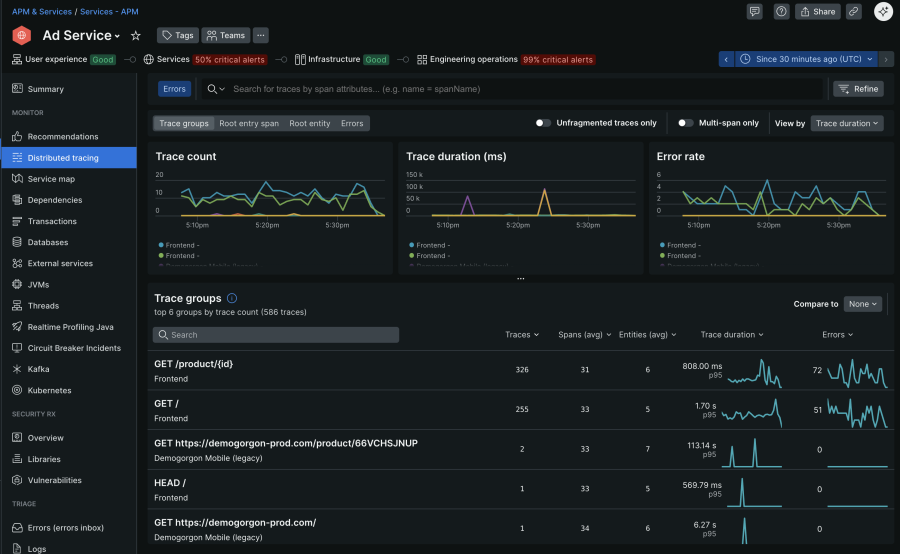
在复杂的分布式系统中,错误通常发生在远离它们出现的地方。分布式跟踪可跨微服务、后端和外部 API 捕获请求的完整旅程,因此团队可以查明故障或延迟峰值的来源。筛选错误跟踪时,可以发现发生故障的特定服务或范围,并检查 HTTP 状态代码或自定义应用标记等元数据。这直接切入根本原因,即使症状出现在其他地方。下图显示了 New Relic 中“广告服务”应用程序的分布式跟踪 UI。
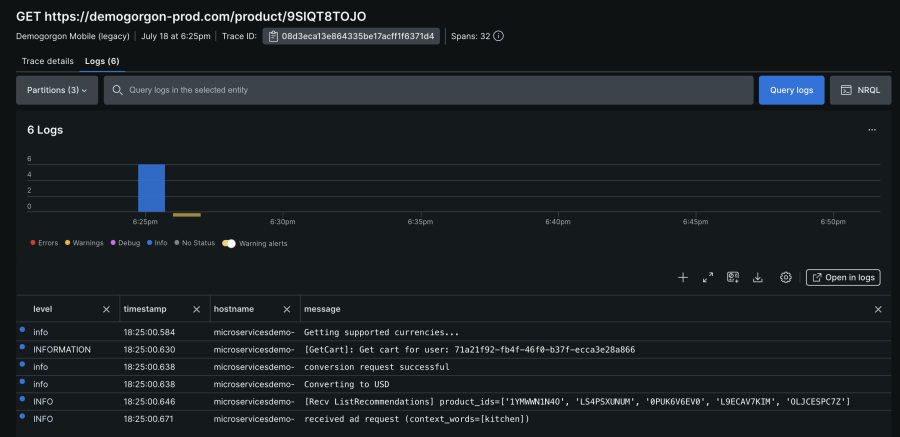
可以进一步向下钻取到任何特定跟踪组,以查看跟踪详细信息或与之关联的日志。下图显示了与 New Relic 中的示例跟踪关联的“日志”。
在我们的文档中了解有关了解和使用 New Relic 中的分布式跟踪 UI 的更多信息 。
日志本身只能讲述故事的一部分。通过上下文中的日志 ,New Relic 将您的日志条目直接连接到相关的 UI 视图,包括 APM 摘要、错误收件箱、分布式跟踪和基础设施监控。 启用后,您的 APM、基础设施或 OpenTelemetry 代理会自动使用关键元数据(如 trace.id、span.id、 hostname 和 entity.guid)装饰日志 .这样可以准确查看特定跟踪或错误期间发生的日志,而无需手动查询或交叉引用 ID。
在实践中,您可能正在调查失败的事务,并立即看到该视图中嵌入的相关日志条目,并完成了丰富的上下文。这减少了分类时间,并有助于快速确认根本原因
拥有正确的工具只是等式的一部分。预防事件并在事件发生时有效响应,需要改变团队处理可靠性的方式。这是关于将可观测性变成一种日常实践,而不仅仅是你在危机期间寻求的东西。
从团队如何跟踪可靠性目标到如何审查事件,主动错误管理从习惯开始。以下是一些有助于建立基础的策略:
使用 SLI 和错误预算定义可靠性
设置明确的服务级别指标 (SLI) 以确保可靠性,例如错误率、延迟和正常运行时间。这些 SLI 应由错误预算支持,这些预算描述了在影响交付优先级之前可以容忍多少故障。这有助于团队有意识地进行权衡,并使他们的工作与性能和稳定性的业务期望保持一致。
使错误更易于理解
当错误在没有上下文的情况下出现时,您只能猜测。添加自定义属性(如用户 ID、请求路径、环境或功能标志状态),将原始信号变成有用的东西。这些属性会自动显示在跟踪和日志中,使根本原因分析更快、更准确。
采用智能告警
静态阈值通常会触发噪声或遗漏实际问题。相反,请使用异常情况检测或基线警报来标记错误率或响应时间的意外变化。理想情况下,警报应与用户体验或 SLI 降级相关联,而不是任意峰值。
自动响应常见故障
对于已知的错误方案,例如部署回滚或服务崩溃,请自动执行响应。实现由预定义错误条件触发的重启脚本、断路器或回滚例程。有证据表明,自动化可以显着缩短解决时间,让团队能够专注于复杂的问题
定期迭代可观测性设置
将仪器和警报视为活生生的人工制品。在回顾或冲刺审查中,问:警报是触发太频繁还是太晚?日志和跟踪中是否缺少关键上下文?随着系统的发展调整代理、仪表板和警报规则。
错误是不可避免的。但长时间中断、反复故障和恢复缓慢并不一定如此。通过投资结构化错误分析,团队可以更快地行动,更清楚地了解问题,并在问题升级之前解决问题。像 New Relic 这样的工具可以通过将错误、跟踪和日志连接到一个工作流程中来发挥关键作用。但更重要的是,这是团队如何使用这些数据。跟踪趋势、嵌入上下文、分享见解并迭代有效的方法,这定义了他们的弹性。
主动错误管理不仅仅是一种技术策略。这就是现代团队保护用户体验、充满信心地交付以及构建在实际条件下保持可靠的系统的方式。
展开阅读全文
︾
读者也喜欢这些内容:

newrelic应用性能监控工具全面解析与佳实践指南
全面解析NewRelic应用性能监控工具的核心功能与实施佳实践,包括实时监控、基础设施管理、用户体验优化等关键方面,帮助...
阅读全文 >
技术优势白皮书
介绍现代企业系统的复杂性使得可观测性对于有效运营至关重要。随着组织采用云原生、混合和分布式基础设施,实时处理和分析遥测数...
阅读全文 >
安装试例
1、注册一个New Relic账号(https://newrelic.com/signup)。2、登录网站选择APM(A...
阅读全文 >
什么是New Relic
🚀 什么是New RelicNew Relic是一款云端性能监控工具,专为应用程序的性能监测而设计。它是一种全...
阅读全文 >


